Incident Report: Analysis of the October 7 server downtime

What happened?
- On October 6, 2022, at 23:00 UTC the server started to fail to respond to some isolated requests resulting in occasional timeouts
- On October 7, 2022, at 00:46 UTC the server started to time out almost all requests
- On October 7, 2022, at 06:22 UTC normal operation of the server was resumed
- During the incident, no commands could be issued or received by the timer software. Existing data was not affected.
The timeline of events can be followed on the public status page: https://stats.uptimerobot.com/jJ140cjvEB
What was the problem?
Stagetimer is running inside a docker container on a shared server with other processes. One process (most likely unrelated to Stagetimer) became faulty and at 00:46 UTC filled up the entire available memory of 32 GB. Even though the server kept running, it was not able to handle requests on time due to the maxed-out memory, resulting in timeouts.
The server monitoring picked up on the outage but wasn’t able to notify the team because the SMS alert credits ran out. Unfortunately, this resulted in longer downtime than usual.
At 06:22 UTC the server was finally rebooted and services were carefully restarted. Since then the server is running well and is carefully monitored.
What are we doing to avoid the problem in the future?
- We’ll move Stagetimer to its own dedicated cloud server.
- We’ll set up an exact replica of the database and server environment on a backup server with automatic failover.
- We’ll revisit our existing monitoring solution and make sure the team is properly alerted in case of server downtime.
Closing thoughts
We are very sorry for any inconvenience caused by the server outage. We are aware that stagetimer.io is used in time-critical settings and that downtime can result in essential disturbances of live events.
Please feel free to get in contact: https://stagetimer.io/contact/
Update (2022-12-12)
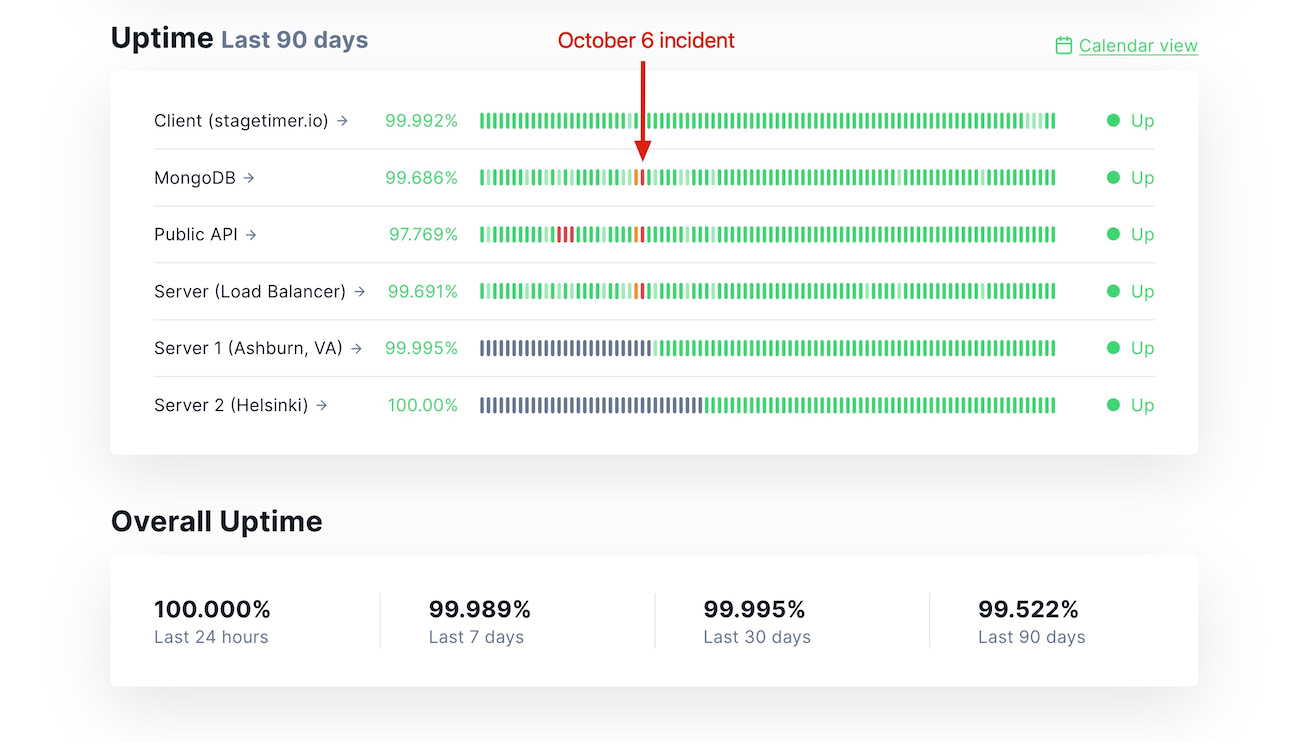
During the past two months, we have made multiple improvements to Stagetimer’s server architecture to improve its reliability and performance. You can read more about these updates and the steps we took to address the incident in our product update article. As a result of these improvements, Stagetimer’s service availability during the last 30 days has been 99.995%, as can be seen here. We are committed to continuing to improve and develop Stagetimer, and to making it the best remote-controlled countdown timer available. We apologize for any inconvenience or disruption that the incident may have caused, and we look forward to working together to make Stagetimer even better.